
Identifying unknown words in spoken dialogue systems by phoneme-level word segmentation
A step toward spoken dialogue systems that learn words through spoken dialogue
A team of researchers led by Assistant Professor Ryu TAKEDA from the Institute of Scientific and Industrial Research, Osaka University, have developed a method that uses phoneme-level word segmentation that employs subword information to capture patterns as “words” so that computers can identify unknown words in spoken language systems.
Many conversation robots and voice assistant apps have appeared in recent years; however, in these systems, computers basically recognize words based on what has been preprogrammed. When unknown words (out-of-vocabulary (OOV)) are included in spoken dialogues, they are replaced with a group of known words, so computers cannot accurately recognize them as words. If computers can accurately recognize a part of an unknown word, they can learn the meaning of the word by asking humans.
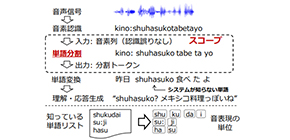
In natural language processing technology to identify unknown words during spoken dialogues, word segmentation from phoneme sequences is essential. The team applied an unsupervised word segmentation method used for a Pitman-Yor semi-Markov model (PYSMM) to the identification of unknown words during spoken dialogues with users.
While the PYSMM uses a character-level word segmentation for the identification of unknown words, the team’s method uses a phoneme-level unsupervised word segmentation method. Because the obtained vocabularies, however, still include meaningless entries due to insufficient cues for phoneme sequences, they focused on using subword information to capture patterns as “words.” They proposed 1) a model based on subword N-gram and subword estimation using a vocabulary set, and 2) posterior fusion of the results of a PYSMM and their model to take advantage of both.
“Subword information is calculated using “wordlikeness,” as a “phoneme-level segmentation.” Since these patterns can be calculated by using the same phoneme in multiple words and locations of appearance, it becomes easier to identify unknown words that are phonetically similar to known words.
On the assumption that phoneme sequences were accurately recognized, the researchers verified their method’s identification rate of unknown words by using conversational corpora in English and Japanese, respectively, demonstrating that their method outperformed the PYSMM which has been applied to character-level segmentation.
Moving forward, as spoken dialogue systems spread in society, computers will need to speak while learning what and how to speak through dialogue with users. Their results will be necessary for realizing not only interactions that can be prepared or updated by developers in advance, but also spoken dialogue systems that become smarter through conversation with humans.

Figure 1
The article, “Word Segmentation from Phoneme Sequences based on Pitman-Yor Semi-Markov Model Exploiting Subword Information”, was published in Proceedings of the IEEE Workshop on SpokenLanguage Technology at DOI: https://doi.org/10.1109/SLT.2018.8639607 .
Related links