
「空気を読んで話す」対話システム研究用データセットHazumi を公開
研究成果のポイント
・ことばの内容だけでなく、声色や表情、姿勢なども使って相手の様子を読み取る音声対話システム(音声を使って話をする人工知能)の研究開発に使えるデータセットを公開
・人工知能の研究開発を進めるには、人とシステムが話すデータやそれに対して人間が付与した正解ラベルが必要であるが、個人情報保護などから公開されたものは少ない
・ことばの内容だけではなく、ニュアンスや雰囲気も扱えるマルチモーダル対話システムの研究開発に向けた共通基盤データとして利用可能
概要
大阪大学産業科学研究所の駒谷和範教授らの研究グループは、マルチモーダル 対話システム の研究開発に利用可能なデータセットHazumiを2020年8月18日に公開しました。
近年、音声応答を行うロボットやアプリが数多く公開されていますが、その多くは音声認識によって得られるテキストのみに基づいて応答します。これに対して人間は、ことばの内容だけではなく、声色や表情、姿勢などから相手の様子を読み取って話しています。このような機能を持った対話システムをマルチモーダル対話システムと呼びます。この研究にはデータが必要ですが、顔の映像は個人情報であり、この点へ配慮が必要であることなどから、人とシステムとの間でのマルチモーダル対話データで公開されたものはほぼありませんでした。
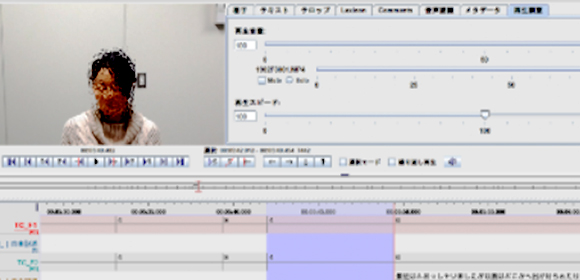
今回、人とシステムとの15分程度のマルチモーダル対話データ59名分を公開しました。システムはWizard-of-Oz方式と呼ばれる、人間が別室でシステムを操作する方式を用いました。公開されたデータには、収録した動画だけではなく、様々なアノテーション が付与されています。例えば、心象(どの程度実験参加者が対話を楽しんでいるか)7段階や、話題継続(システム役が話題を続けるべきかどうか)7段階、話題への興味度3段階などです。これらが、システム発話とユーザ発話の対(交換)を単位として、第三者である5名により対話中の全交換に対して付与されています。また心象は、実験参加者本人が事後に付与したものも含まれます。また実験参加者全員から同意書を得ており、その手続きは研究倫理委員会により承認されたものです。
これにより、ことばの内容のやりとりだけではなく、ニュアンスや雰囲気も扱えるマルチモーダル対話システムの研究開発に向けて、共通基盤データとして広く利用されることが期待できます。
本データは、2020年8月18日(火)から、国立情報学研究所情報学研究データリポジトリにて公開されています。なおHazumiとは、話を弾ませることができるような対話システムを作りたいという願いから名付けたものです。
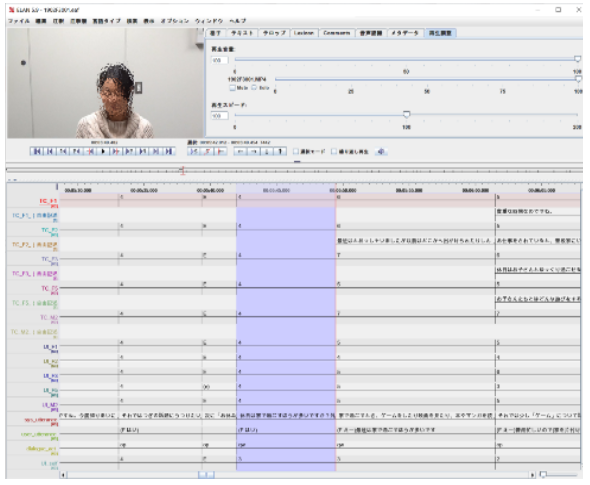
図1 公開したデータの一部
(ここでは顔画像を一部加工.公開データは論文や学会発表にはそのまま利用可能.)
研究の背景
近年、音声応答を行うロボットやアプリが数多く公開されていますが、その多くは音声認識によって得られるテキストのみに基づいて応答します。これに対して人間は、ことばの内容だけではなく、声色や表情、姿勢などから相手の様子を読み取って話しています。このような機能を持った対話システムをマルチモーダル対話システムと呼びます。この研究にはデータが必要ですが、顔の映像は個人情報であり、この点へ配慮が必要であることなどから、人とシステムとの間でのマルチモーダル対話データで公開されたものはほぼありませんでした。
ユーザの心的状態をセンシングし有効な情報を取得する研究は、社会的信号処理(Social Signal Processing, SSP)という名前で近年注目を集めています。社会的信号処理では、ユーザの内面の発露として現れる情報をコンピュータがセンシングする技術です。様々なセンサ情報を入力特徴量とした機械学習により、例えば「ユーザが現在の話題に興味を示している」のような情報を予測します。本データセットは、対話システム研究と社会的信号処理研究を融合させるという位置づけもあります。
本研究成果が社会に与える影響
本データセットの公開により、ことばの内容のやりとりだけではなく、ニュアンスや雰囲気も扱えるマルチモーダル対話システムの研究開発がさらに進展することが期待されます。また、共通基盤データとして広く利用されることも期待できます。我々も、本データセットを使って、付与されたアノテーション内容の機械学習 による予測をより高精度にする研究や、さらに生体信号を併用して実験参加者の心象を得る研究などに活用しています。
特記事項
本データセットは、2020年8月18日(火)から、国立情報学研究所情報学研究データリポジトリにて公開されています。
タイトル: 大阪大学 マルチモーダル対話コーパス(Hazumi)
著者名: 駒谷和範、岡田将吾
https://www.nii.ac.jp/dsc/idr/rdata/Hazumi/
http://doi.org/10.32130/rdata.4.1
本データセットを利用した研究は、2019年10月15日に、マルチモーダルインタラクションに関する国際会議ICMI(The 21st ACM International Conference on Multimodal Interaction)にて講演発表し、優秀論文賞(Best Paper Runner-up Award)を受賞しました。
Yuki Hirano, Shogo Okada, Haruto Nishimoto, Kazunori Komatani:
Multitask Prediction of Exchange-level Annotations for Multimodal Dialogue Systems.
International Conference on Multimodal Interaction (ICMI), pp.85-94, Oct., 2019.
(Best Paper Runner-ups Award)
また本データセットの次期バージョンを利用した研究成果は、2020年10月25日 から29日に開催される国際会議ICMI(The 22nd ACM International Conference on Multimodal Interaction)にて発表予定です。
Shun Katada, Shogo Okada, Yuki Hirano, Kazunori Komatani:
Is She Truly Enjoying the Conversation?: Analysis of Physiological Signals toward Adaptive Dialogue Systems.International Conference on Multimodal Interaction (ICMI), (accepted), 2020.
本研究は、北陸先端科学技術大学院大学先端科学研究科岡田将吾准教授との協力の下で行われました。本研究の一部は、物質・デバイス領域共同研究拠点における「人・環境と物質をつなぐイノベーション創出ダイナミック・アライアンス」共同研究プログラムの支援を受けました。
研究者のコメント
人工知能、特に様々な人と話をする対話システムでは、大量一括生産型ではなく、個々の人間に適応できる能力が重要になります。人や社会から信頼される対話システムはきっと、あなたの様子を察知して答えたり、話を聞いたりしてくれるでしょう。本データセットは、そのようなマルチモーダル対話システムの研究開発に資するものです。
参考URL
産業科学研究所 駒谷研究室HP
http://www.ei.sanken.osaka-u.ac.jp/
用語説明
- 対話システム
人とことばを用いて話をするシステムで、人工知能のひとつです。音声を入力とした音声応答アプリや対話をするロボット、テキストを入力として雑談をするチャットボットが最近多く開発されています。会話システムとも呼ばれます。
- マルチモーダル
テキストだけでなく、聴覚から得られる声色や、視覚から得られる表情など、複数の情報を利用することです。
- アノテーション
データに対して人間が注釈をつけたものです。昨今広く使われている機械学習では、人間が与えた情報を正解データとして学習を行うものが多いです。このため、データだけではなく、それに対して人手で注釈をつけたものが研究開発において有用です。
- 機械学習
データに基づいて推論や判断を自動で行えるようにするための技術で、人工知能の技術のひとつです。機械学習には、教師あり学習、教師なし学習、強化学習があります。教師あり学習は、状況と正解を与えることでそれらを繋ぐように学習が行われ、別の状況に対する判断をできるようにする学習方法です。