
Hazumi datasets for dialogue systems that recognize human sentiment released
A group of researchers from Osaka University has released multimodal human-system dialogue corpora Hazumi on the Informatics Research Data Depository of the National Institute of Informatics (NII). Currently, two datasets in Japanese are available for research and development (R&D) purposes of multimodal spoken dialogue systems (SDS), in which an artificial intelligence (AI) system speaks while recognizing a user’s states using their multimodal features, including verbal contents, facial expressions, body and head motions, and acoustic features.
Most current communication robots and applications respond using speech to text conversion (automatic speech recognition), whereas humans speak while recognizing the conversational partner’s nonverbal features. Various social signals are used in human conversations. Although human-system spoken dialogue data and human interpretations to them are necessary for R&D of such AI systems, few data have been released because they contain personal information such as facial images.
This group has been engaged in the development of a multimodal dialogue system based on predicting users’ sentiment using Social Signal Processing (SSP) techniques and reinforcement learning. They conducted multimodal computational modeling of sentiment labels that are annotated per exchange of human-system dialogue by using SSP techniques. SSP techniques are used for modeling, analysis, and synthesis of social signals in human–machine interactions. Computer models analyze sensor data by machine learning algorithms to understand a human’s social behavior, predicting the user’s sentiment such as interest in the current topic.
This group collected data from 59 participants when they talked with a system operated with the Wizard of Oz (WoZ) method, in which a virtual agent was manipulated by an operator, called a "Wizard." The duration of the data was about 15 minutes per participant. Recently, they released the data that they collected in their studies.
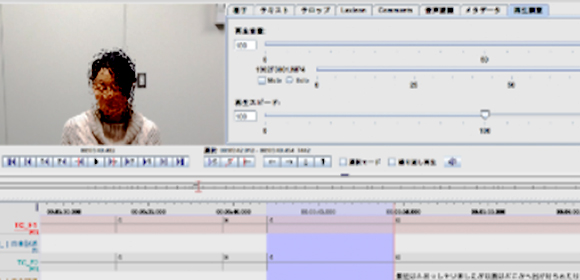
The released datasets include both videos of dialogues between the WoZ system and a user (participant) and annotations to them. The annotation is applied to every exchange of dialogue (i.e., a pair of a system utterance and a user utterance) by observers and can be used as reference labels for constructing a system that can adapt to user multimodal behaviors.
The annotated labels include the score (0-2) of (1) the user’s interest label pertaining to the current topic, the score (1-7) of (2) the user’s sentiment label, and the score (1-7) of (3) topic continuance denoting whether the system should continue the current topic or change it. The labels were given to each exchange by annotators. The annotated score also includes the sentiment label given by users themselves. The group obtained consent from the participants concerning the use of their facial images according to the procedures approved by the research ethics committee.
Lead author Professor Komatani says, “AI, especially dialogue systems by which computers talk with various people, requires the ability to respond to user utterance by recognizing the user’s states. Hazumi, in which dialogue system research and SSP are merged, will help the R&D of multimodal dialogue systems and be used as a shared R&D infrastructure for such systems.”

Figure 1. An example of the released data
The above face photo is digitally edited, but participants’ raw videos in the released data can be used for technical papers and presentations at technical conferences
The multimodal dialogue corpus (Hazumi) in the Informatics Research Data Repository of the National Institute of Informatics was published at http://doi.org/10.32130/rdata.4.1 .
Related Links