視覚・生理・言語情報を統合し「感情概念」を形成する計算モデルを開発
ヒトの情動を理解し、有効なコミュニケーションの構築に期待
概要
奈良先端科学技術大学院大学(学長:塩﨑一裕)先端科学技術研究科 情報科学領域の日永田智絵助教、大阪大学(総長:熊ノ郷淳)大学院基礎工学研究科の弦牧和輝さん(研究当時:大学院生)、宮澤和貴助教は、人間の感情がどのように形成され、人間の内部で意味づけられるのかという長年の問いに対し、工学的アプローチを用いて機能的に説明する計算モデルを開発しました。本研究では、視覚情報・生理反応・言語情報といった多様な様式の情報を統合的に学習して潜在的な概念を推測する「Multi-layered Multimodal Latent Dirichlet Allocation(mMLDA)」を活用し、個人の経験に基づいて感情概念を形成・推定する計算モデルを構築しました。
研究チームが構築したモデルは、被験者が画像を見た際に報告した感情評価と約75%の精度で一致する感情カテゴリを形成できることが確認されました。さらに、モデルは未観測の情報を推定する機能を持ち、例えば画像や言語情報から生理反応を推定したり、生理反応のみから使用される感情語を推測するなど、人間の情動処理と類似した推論能力を示しました。これらの結果は、計算論的視点から、人間の感情形成が身体の内外の様々な情報を組み合わせることで実現される、という仮説の妥当性を示します。
本成果は、次世代ロボットの情動理解、感情推定AI、医療・福祉領域のメンタルヘルス支援技術、さらにはヒトとAIの協働社会実現に向けた基盤知として高い応用価値を持ちます。
本研究成果は、情動計算学分野で国際的影響力の高い学術誌IEEE Transactions on Affective Computingの16-4号に2025年11月26日(水)に公開されました(DOI:10.1109/TAFFC.2025.3585882)。
研究の背景
人間の感情は古くから心理学・神経科学・哲学・人工知能研究など多様な分野で議論されてきました。その中でも近年注目を集めている「構成主義的情動/感情理論」では、感情は生得的に決まっているものではなく、身体感覚(内受容感覚)、外界から得られる知覚情報、そして言語や文化などの知識構造が後天的に統合されることで、人間内部で「概念」として構築されると説明されています。さらに、構成主義的情動/感情理論では、感情は固定的なラベルではなく、経験をもとに形成・更新され続ける柔軟な知識体系であると位置づけています。
しかしながら、感情がどのような情報処理過程を経て概念として形成されるのかという問いについては、理論的枠組みが存在する一方、その計算過程の検証は十分に行われていませんでした。
本研究は、まさにこの「人間の感情がどのように生まれ、概念化されるのか」という未解明領域に対し、工学的・構成論的アプローチを用いて具体的な計算プロセスとして感情概念形成を表現することを目的としました。
研究の内容
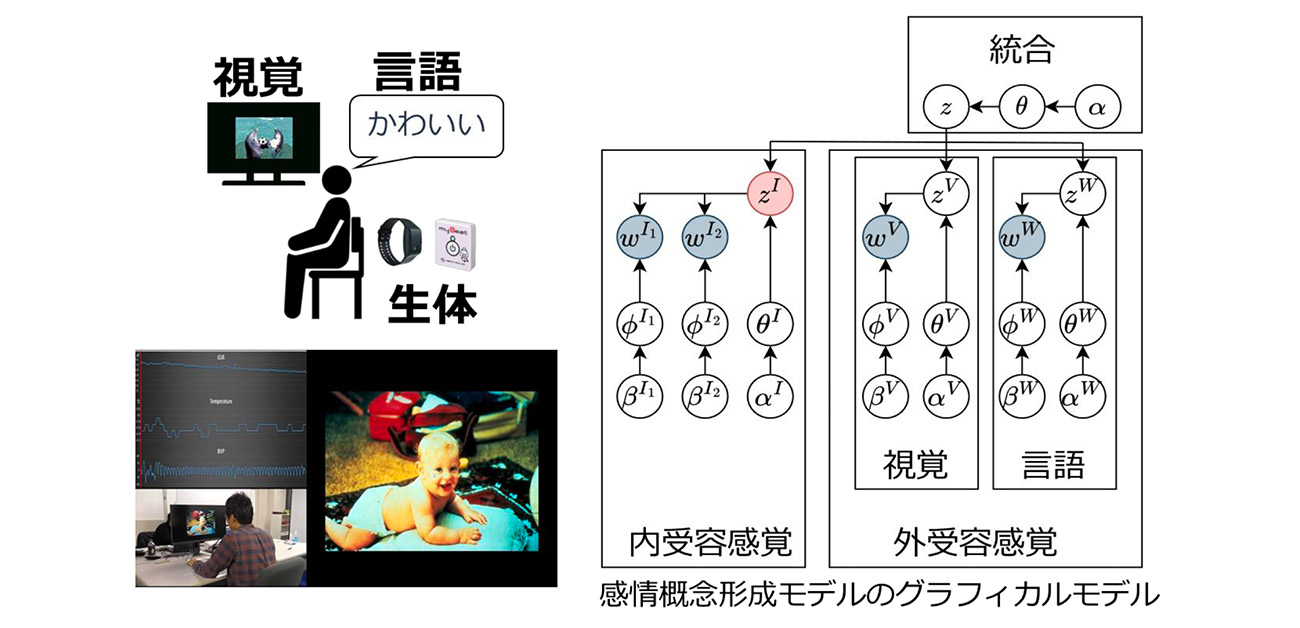
¥本研究では、29名の人被験者に対して、心理評価研究で広く用いられる感情喚起画像セットInternational Affective Picture System(IAPS)に収録された60枚の画像を提示し、画像から抽出した視覚特徴量、刺激提示中の生理反応(皮膚電気活動および心拍変動)、そして被験者が自由に入力した言語データを収集しました。これらはそれぞれ、外界知覚情報(視覚)、内受容情報(生理)、意味情報(言語)を反映する異なる情報源であり、人間が感情を判断する際に依拠すると考えられている主要要素でもあります。
これらの情報をmMLDAモデル(図1)に学習させた結果、モデル内部に形成された感情概念が、被験者自身による主観評価(快–不快・覚醒レベルに基づく感情カテゴリ)と約75%の精度で一致しました(図2)。この一致率は、偶然的分類(チャンスレベル)を大きく上回っており、モデルが有意に主観評価に類似した感情概念を形成したことを示します。
図1. 感情刺激画像の提示実験およびmMLDAのグラフィカルモデル
図2. モデルの出力結果
左図:ランド指数に基づく主観評価との一致率の評価
右図:モデルの感情概念をt-distributed Stochastic Neighbor Embedding (t-SNE)により二次元に可視化
さらにモデルは、与えられた情報から未観測の情報を推定することが可能であり、例えば画像や言語から生理反応を推定したり、生理反応から使用される感情語を推測するなど、人間の認知特性に近い推論機能を示しました。この結果は、感情が単一の要因ではなく、複数の知覚・内受容・言語情報を統合することで形成されるという理論的仮説と整合しています。
今後の展開
本モデルは、単に感情を識別する技術ではなく、人間が世界をどのように理解し、意味づけ、感情を経験しているのかという仕組みを理解するためのツールとして設計されています。そのため今後は、対話型ロボットや生活支援AI、医療分野における心理支援などに応用することで、人間の行動や発話の背後にある情緒・意図を推定し、より自然で文脈依存型のコミュニケーションを可能とする技術基盤につながることが期待されます。
また、言語化が困難な情動体験を外部から推定できる特性を活かし、発達障害支援、認知症ケア、セルフメンタルヘルスアセスメント、教育現場における情緒理解、さらにはストレス検知や心理状態モニタリングといった臨床応用への可能性が広がります。
将来的には視覚情報に加え、触覚、嗅覚、音響情報、社会文脈、文化背景などを統合し、より高度な情動モデルへ発展させることで、「ヒトの感情を理解するAI」の実現を目指します。
特記事項
【論文情報】
タイトル:Study of Emotion Concept Formation by Integrating Vision, Physiology, and Word Information using Multilayered Multimodal Latent Dirichlet Allocation
著者:Kazuki Tsurumaki, Chie Hieida and Kazuki Miyazawa
掲載誌:IEEE Transactions on Affective Computing
DOI:10.1109/TAFFC.2025.3585882
用語説明
- Multi-layered Multimodal Latent Dirichlet Allocation (mMLDA)
複数種類の情報(視覚・生理・言語など)を階層的に統合し、潜在構造を推定する計算モデル。
- International Affective Picture System (IAPS)
国際的に心理研究で用いられる標準化された感情刺激画像セット。
- t-distributed Stochastic Neighbor Embedding (t-SNE)
高次元データを2次元や3次元の低次元に落とし込むための次元削減アルゴリズム。